https://www.youtube.com/watch?v=2oFx3DPf_Uo&t=5s
https://colab.research.google.com/drive/19Xq9UE_qi8jx8xLeHuW2GohPpdQmKvai?usp=sharing
_9 합성곱 신경망(Convolution Neural Network).ipynb
Colaboratory notebook
colab.research.google.com
합성곱 신경망(Convolution Neural Network)
- 이미지 인식, 음성 인식 등에 자주 사용되는데,
특히, 이미지 인식 분야에서 거의 모든 딥러닝 기술에 사용
컨볼루션 신경망의 등장
- 1989년 얀 르쿤(Yann LeCun) 교수의 논문에서 발표
- 필기체 인식에서 의미가 있었지만 범용화하는데에는 무리
- 1998년, "Gradient-Based Learning Applied to Document Recognition"이라는 논문에서 LeNet-5 제시
- 합성곱 층(convolution layer), 풀링 층(pooling layer) 소개
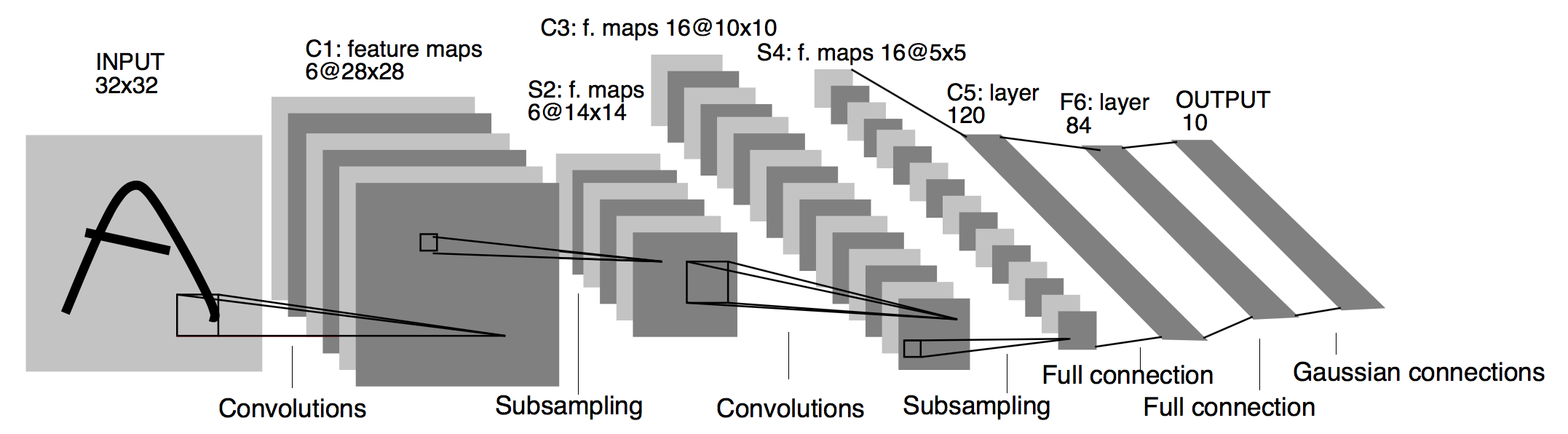
Key Deep Learning Architectures: LeNet-5
LeNet-5 [1998, paper by LeCun et al.]
medium.com
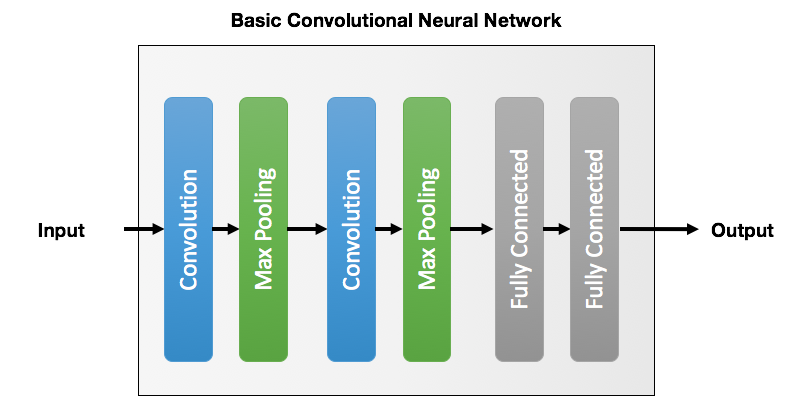
컨볼루션 신경망 구조 예시
합성곱 연산
- 필터(filter) 연산
- 입력 데이터에 필터를 통한 어떠한 연산을 진행
- 필터에 대응하는 원소끼리 곱하고, 그 합을 구함
- 연산이 완료된 결과 데이터를 특징 맵(feature map)이라 부름
- 필터(filter)
- 커널(kernel)이라고도 칭함
- 흔히 사진 어플에서 사용하는 '이미지 필터'와 비슷한 개념
- 필터의 사이즈는 "거의 항상 홀수"
- 짝수이면 패딩이 비대칭이 되어버림
- 왼쪽, 오른쪽을 다르게 주어야함
- 중심위치가 존재, 즉 구별된 하나의 픽셀(중심 픽셀)이 존재
- 필터의 학습 파라미터 개수는 입력 데이터의 크기와 상관없이 일정
따라서, 과적합을 방지할 수 있음


- 일반적으로, 합성곱 연산을 한 후의 데이터 사이즈는(n−f+1)×(n−f+1)
- n : 입력 데이터의 크기
- f : 필터(커널)의 크기

- 위 예에서 입력 데이터 크기(n)는 5, 필터의 크기(k)는 3이므로 출력 데이터의 크기는 (5−3+1)=3
패딩(padding)과 스트라이드(stride)
- 필터(커널) 사이즈과 함께 입력 이미지와 출력 이미지의 사이즈를 결정하기 위해 사용
- 사용자가 결정할 수 있음
패딩
- 입력 데이터의 주변을 특정 값으로 채우는 기법
- 주로 0으로 많이 채움
- 출력 데이터의 크기


- 위 그림에서, 입력 데이터의 크기(n)는 2, 필터의 크기(f)는 3, 패딩값(p)은 2이므로
출력 데이터의 크기는 (2+2×2−3+1)=4
'valid' 와 'same'
- 'valid'
- 패딩을 주지 않음
- padding=0 (0으로 채워진 테두리가 아니라 패딩을 주지 않는다는 의미)
- 'same'
- 패딩을 주어 입력 이미지의 크기와 연산 후의 이미지 크기를 같게함
- 만약, 필터(커널)의 크기가 k 이면,
패딩의 크기는 p=k−12 (단, stride=1)
스트라이드
- 필터를 적용하는 간격을 의미
- 아래는 그림의 간격 2

출력 데이터의 크기
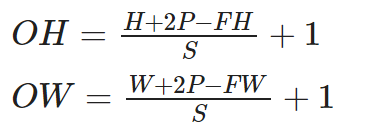
- 입력 크기 : (H,W)
- 필터 크기 : (FH,FW)
- 출력 크기 : (OH,OW)
- 패딩, 스트라이드 : P,S
- (주의)
- 위 식의 값에서 (H+2P−FH) / S 또는 (W+2P−FW) / S가 정수로 나누어 떨어지는 값이어야 함
- 만약, 정수로 나누어 떨어지지 않으면 패딩, 스트라이드값을 조정하여 정수로 나누어 떨어지게 해야함
풀링(Pooling)
- 필터(커널) 사이즈 내에서 특정 값을 추출하는 과정
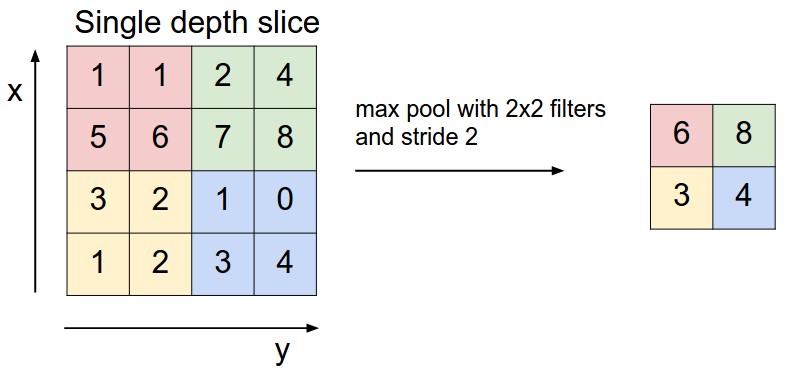
맥스 풀링(Max Pooling)
- 가장 많이 사용되는 방법
- 출력 데이터의 사이즈 계산은 컨볼루션 연산과 동일OW=W+2P−FWS+1
- OH=H+2P−FHS+1
- 일반적으로 stride=2, kernel_size=2 를 통해 특징맵의 크기를 절반으로 줄이는 역할
- 모델이 물체의 주요한 특징을 학습할 수 있도록 해주며, 컨볼루션 신경망이 이동 불변성 특성을 가지게 해줌
- 예를 들어, 아래의 그림에서 초록색 사각형 안에 있는 2와 8의 위치를 바꾼다해도 맥스 풀링 연산은 8을 추출
- 모델의 파라미터 개수를 줄여주고, 연산 속도를 빠르게 해줌
Conv1D
자연어처리에서는 2D보다 1D 많이 사용한다!
- 텍스트 분류나 시계열 예측 같은 간단한 문제, 오디오 생성, 기계 번역 등의 문제에서 좋은 성능
- 타임스텝의 순서에 민감하지 X
- 2D Convolution
- 지역적 특징을 인식
-

- 1D Convolution
- 문맥을 인식

Conv1D Layer
- 입력: (batch_size, timesteps, channels)
- 출력: (batch_size, timesteps, filters)
- 필터의 사이즈가 커져도 모델이 급격히 증가하지 않기 때문에 다양한 크기를 사용할 수 있음
- 데이터의 품질이 좋으면 굳이 크기를 달리하여 여러 개를 사용하지 않아도 될 수도 있음
MaxPooling1D Layer
- 다운 샘플링 효과
- 단지 1차원형태로 바뀐 것 뿐
GlovalMaxPooling Layer
- 배치차원을 제외하고 2차원 형태를 1차원 형태로 바꾸어주는 레이어
- Flatten layer로 대신 사용가능
IMDB 데이터
데이터 로드 및 전처리
# IMDB
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.layers import Dense, Embedding, Conv1D, MaxPooling1D, GlobalMaxPooling1Dnum_words = 10000
max_len = 500
batch_size = 32
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = num_words)
print(len(x_train), len(x_test)) # 25000 25000# 패딩
pad_x_train = pad_sequences(x_train, maxlen=max_len)
pad_x_test = pad_sequences(x_test, maxlen=max_len)
print(pad_x_train.shape, pad_x_test.shape) #(25000, 500) (25000, 500)모델 구성
# 모델 구성
def build_model():
model = Sequential()
model.add(Embedding(input_dim=num_words, output_dim=32, input_length=max_len))
model.add(Conv1D(32,7,activation='relu'))
model.add(MaxPooling1D(7))
model.add(Conv1D(32,5,activation='relu'))
model.add(MaxPooling1D(5))
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
return modelmodel = build_model()
model.summary()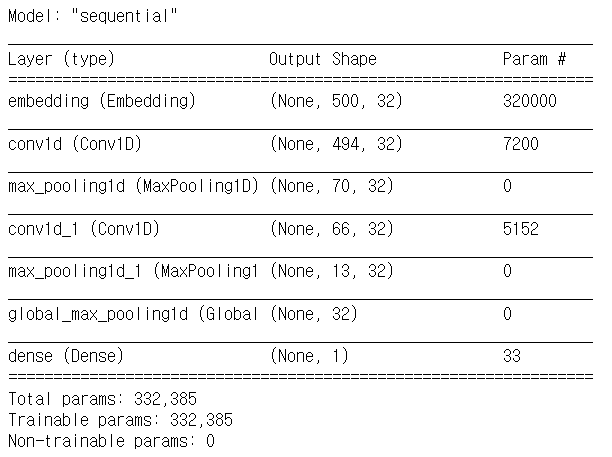
모델 학습
# 모델 학습
history = model.fit(pad_x_train, y_train, batch_size=128, epochs=30, validation_split=0.2)시각화
# 시각화
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'b-', label = 'training loss')
plt.plot(epochs, val_loss, 'r:', label = 'validation loss')
plt.grid()
plt.legend()
plt.figure()
plt.plot(epochs, acc, 'b-', label = 'training loss')
plt.plot(epochs, val_acc, 'r:', label = 'validation loss')
plt.grid()
plt.legend()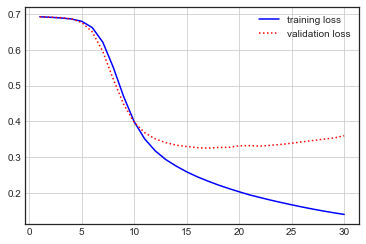

모델 평가
# 모델 평가
model.evaluate(pad_x_test, y_test) # [0.3796456754207611, 0.8501999974250793]Reuters 데이터
데이터 로드 및 전처리
# Reuters
from tensorflow.keras.datasets import reuters
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.layers import Dense, Embedding, Conv1D, MaxPooling1D, GlobalMaxPooling1Dnum_words = 10000
max_len = 500
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words = num_words)
print(len(x_train), len(x_test)) # 8982 2246# 패딩
pad_x_train = pad_sequences(x_train, maxlen=max_len)
pad_x_test = pad_sequences(x_test, maxlen=max_len)
print(pad_x_train.shape, pad_x_test.shape) #(8982, 500) (2246, 500)
모델 구성
# 모델 구성
def build_model():
model = Sequential()
model.add(Embedding(input_dim=num_words, output_dim=64, input_length=max_len))
model.add(Conv1D(64,7,activation='relu'))
model.add(MaxPooling1D(7))
model.add(Conv1D(64,5,activation='relu'))
model.add(MaxPooling1D(5))
model.add(GlobalMaxPooling1D())
model.add(Dense(46, activation='softmax')) # reuters는 다중분류 -> 시그모이드X
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return modelmodel = build_model()
model.summary()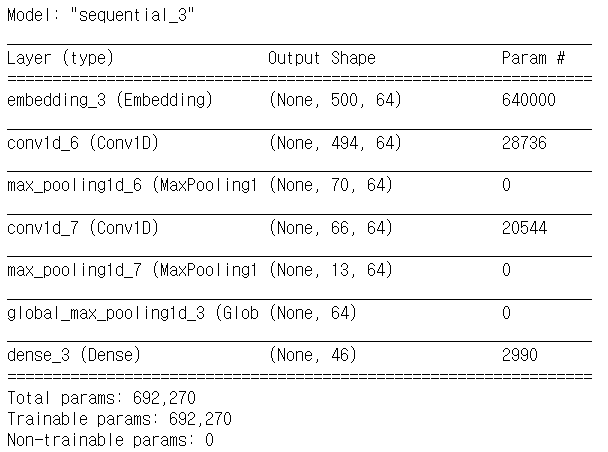
모델 학습
# 모델 학습
history = model.fit(pad_x_train, y_train, batch_size=128, epochs=30, validation_split=0.2)시각화
# 시각화
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'b-', label = 'training loss')
plt.plot(epochs, val_loss, 'r:', label = 'validation loss')
plt.grid()
plt.legend()
plt.figure()
plt.plot(epochs, acc, 'b-', label = 'training loss')
plt.plot(epochs, val_acc, 'r:', label = 'validation loss')
plt.grid()
plt.legend()
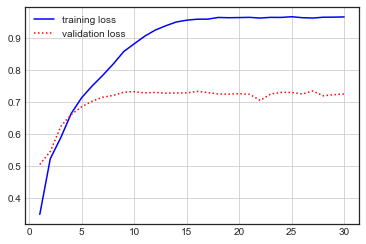
모델 평가
# 모델 평가
model.evaluate(pad_x_test, y_test) # [1.7515205144882202, 0.7359750866889954]'Computer > ML·DL·NLP' 카테고리의 다른 글
| [이수안컴퓨터연구소] CNN 스팸 메일 분류 (0) | 2022.01.31 |
|---|---|
| [이수안컴퓨터연구소] 케라스 Word2Vec Skipgram, CBOW 구현 (0) | 2022.01.31 |
| [이수안컴퓨터연구소] 순환 신경망 Recurrent Neural Network (0) | 2022.01.10 |
| [이수안컴퓨터연구소] 임베딩 Embedding (0) | 2022.01.08 |
| [이수안컴퓨터연구소] 토픽 모델링 Topic Modeling (0) | 2022.01.08 |




댓글