https://colab.research.google.com/drive/1bkzZh_JbjatK-47sF8LUaEhzWwLT-RSD?usp=sharing
_9.1 CNN 스팸 메일 분류.ipynb
Colaboratory notebook
colab.research.google.com
CNN 스팸 메일 분류
CNN의 Conv1D 사용해서 스팸메일을 분류해봅시당.
데이터 로드 및 전처리
# 데이터 로드, 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencesimport urllib.request
urllib.request.urlretrieve('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', filename='spam.csv')
data = pd.read_csv('spam.csv', encoding='latin-1')
print(len(data)) # 5572

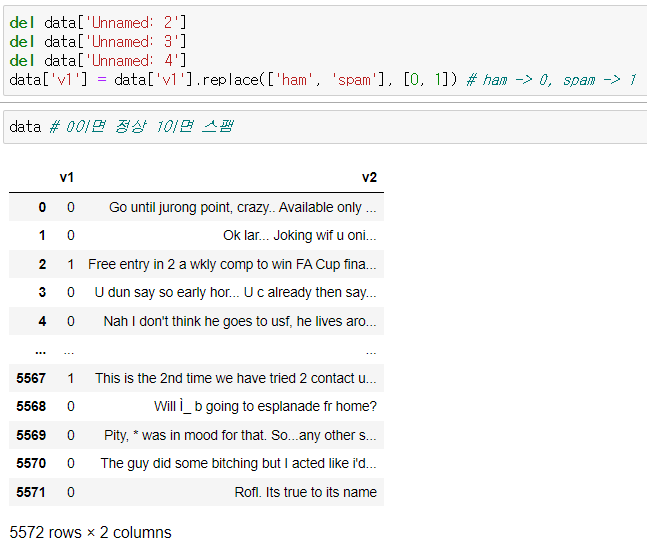
data.drop_duplicates(subset=['v2'], inplace=True)
len(data) # 5169개로 줄어듦data['v1'].value_counts().plot(kind='bar') # 정상메일이 스팸보다 많음

학습데이터 만들기
X_data = data['v2']
y_data = data['v1']vocab_size = 1000
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(X_data) # 토큰화
sequences = tokenizer.texts_to_sequences(X_data) # 토큰에 인덱스 추가X_data = sequences
print('메일 최대 길이 : {}'.format(max(len(l) for l in X_data)))
print('메일 평균 길이 : {}'.format(sum(map(len, X_data))/len(X_data)))
# 메일 최대 길이 : 172
# 메일 평균 길이 : 12.566840781582512plt.hist([len(s) for s in X_data], bins = 50)
plt.xlabel('Length of Samples')
plt.ylabel('Number of Sampled')
plt.show()
max_len = 60
data = pad_sequences(X_data, maxlen = max_len)
print(data.shape) # (5169, 60)n_train = int(len(sequences)*0.8)
n_test = int(len(sequences) - n_train)
print(n_train) # 4135
print(n_test) # 1034X_train = data[:n_train]
y_train = np.array(y_data[:n_train])
X_test = data[n_train:]
y_test = np.array(y_data[n_train:])print(X_train.shape, y_train.shape, X_test.shape, y_test.shape) # (4135, 60) (4135,) (1034, 60) (1034,)모델 구성
# 모델 구성
from tensorflow.keras.layers import Dense, Conv1D, GlobalMaxPooling1D, Embedding,Dropout, MaxPooling1D
from tensorflow.keras.models import Sequential
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpointmodel = Sequential()
model.add(Embedding(vocab_size, 32))
model.add(Dropout(0.2))
model.add(Conv1D(32, 5, strides=1, padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer = 'adam', loss='binary_crossentropy', metrics=['acc'])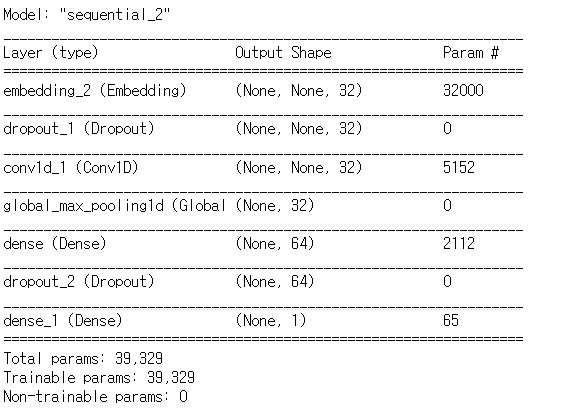
# earlystopping, checkpoints
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=3)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode = 'max', verbose=1, save_best_only=True)모델 학습
# 모델 학습
history = model.fit(X_train, y_train, epochs = 10, batch_size=64, validation_split=0.2, callbacks=[es, mc])시각화
# 시각화
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1, len(loss)+1)
plt.plot(epochs, loss, 'b--', label = 'training loss')
plt.plot(epochs, val_loss, 'r:', label='validation loss')
plt.grid()
plt.legend()
plt.figure()
plt.plot(epochs, acc, 'b--', label = 'training accuracy')
plt.plot(epochs, val_acc, 'r:', label='validation accuracy')
plt.grid()
plt.legend()
plt.show()

잘 작동합니당!
모델 평가
model.evaluate(X_test, y_test) # loss, acc = [0.0685640200972557, 0.9825918674468994]성능이 매우 좋네요~~~
'Computer > ML·DL·NLP' 카테고리의 다른 글
| [NLP] 윈도우 Windows에서 Mecab 사용하기! (주피터 / VSCode / Colab 등등) (0) | 2022.02.28 |
|---|---|
| [이수안컴퓨터연구소] 감정 분석 (0) | 2022.01.31 |
| [이수안컴퓨터연구소] 케라스 Word2Vec Skipgram, CBOW 구현 (0) | 2022.01.31 |
| [이수안컴퓨터연구소] 합성곱 신경망 Convolution Neural Network (0) | 2022.01.11 |
| [이수안컴퓨터연구소] 순환 신경망 Recurrent Neural Network (0) | 2022.01.10 |



댓글