https://www.youtube.com/watch?v=2e9wnwuAVv0&list=PL7ZVZgsnLwEEoHQAElEPg7l7T6nt25I3N
다음 에러로 해당 블로그를 방문하신 분들은 접은 글을 확인해주세용..
ERROR: JPype1-1.3.0-cp310-cp310-win_amd64.whl is not a supported wheel on this platform.
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
----------------------------------------
ERROR: Command errored out with exit status 1: 'c:\users\sheom\appdata\local\programs\python\python38\python.exe
microsoft visual c++ build tools 설치 패키지가 없거나 손상되었습니다
c:\users\sheom\appdata\local\programs\python\python38\include\pyconfig.h(206): fatal error C1083: 포함 파일을 열 수 없습니다. 'basetsd.h': No such file or directory
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\\cl.exe' failed with exit status 2
LINK : fatal error LNK1158: 'rc.exe'을(를) 실행할 수 없습니다.
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\\link.exe' failed with exit status 1158
한국어 처리
정규표현식
- 한국어 정규 표현식도 대부분은 영어와 비슷함.
- 한국어는 자음과 모음이 분리되어 있기 때문에, 문법을 지정할 때는 자음과 모음을 동시에 고려해야 함
match
import re
check = "[ㄱ-ㅎ]+"
print(re.match(check, "ㅎ 안녕하세요.")) # <re.Match object; span=(0, 1), match='ㅎ'>
print(re.match(check, "안녕하세요. ㅎ")) # Nonesearch
- match 와는 다르게 문자열의 전체를 검사
check = '[ㄱ-ㅎ\ㅏ-ㅣ]'
print(re.search(check, 'ㄱㅏ 안녕하세요')) # <re.Match object; span=(0, 1), match='ㄱ'>
print(re.match(check, '안ㄱㅏ')) # None
print(re.search(check, '안ㄱㅏ')) # <re.Match object; span=(1, 2), match='ㄱ'>
sub
- 정규 표현식과 일치하는 부분을 다른 문자열로 교체
print(re.sub('[가-힣]', '가나다라마바사', '1')) # 1
print(re.sub('[^가-힣]', '가나다라마바사', '1')) # 가나다라마바사
토큰화
-한국어 학습 데이터를 사용할 때는 언어의 특성으로 인해 추가적으로 고려해야 할 사항이 존재함
- 한국어는 띄어쓰기를 준수하지 않아도 의미가 전달되는 경우가 많아 띄어쓰기가 지켜지지 않을 가능성이 존재
- 띄어쓰기가 지켜지지 않으면 정상적인 토큰 분리가 이루어지지 않음
- 한국어는 형태로라는 개념이 존재해 추가로 고려해주어야 함
- '그는', '그가' 등의 단어들은 같은 의미를 가리키지만 텍스트 처리에서는 다르게 받아들일 수 있어 처리를 해줘야 함
한국어 자연어 처리 konlpy와 형태소 분석기 MeCab 설치
konlpy를 설치하기 위해서 밑의 링크를 참고했습니다.
설치하기 — KoNLPy 0.5.2 documentation
설치하기 — KoNLPy 0.5.2 documentation
우분투 Supported: Xenial(16.04.3 LTS), Bionic(18.04.3 LTS), Disco(19.04), Eoan(19.10) Install dependencies # Install Java 1.8 or up $ sudo apt-get install g++ openjdk-8-jdk python3-dev python3-pip curl Install KoNLPy $ python3 -m pip install --upgrade p
konlpy.org
1. JDK 다운로드 받고, 설치 누르면 Program Files에 JAVA가 생깁니다.
2. 환경변수 편집을 검색하시고, 나오는 창에서 다음과 같이 시스템 변수를 추가하세요.

참고로 '디렉토리 찾아보기'를 누르셔야 합니다.
3. pip upgrade 해줍니다.
4. Jpype 를 다운로드받습니다. 이 때 정말 중요합니다. 본인의 컴퓨터 bit도 일치해야 하지만, 파이썬도 일치해야 합니다! 저는 3.8인데 최신 버전이 좋겠지~ 하고 310 다운로드받았다가 다음과 같은 오류 코드를 받았습니다
ERROR: JPype1-1.3.0-cp310-cp310-win_amd64.whl is not a supported wheel on this platform.
다시 파이썬에 맞는 것으로 다운로드 받으면 다음과 같이 뜹니다.
JPype 파일을 본인의 working directory로 옮기는 것 잊지 마세요! 저는 홈 디렉토리에서 하다 보니 홈 디렉토리로 옮겼습니다.
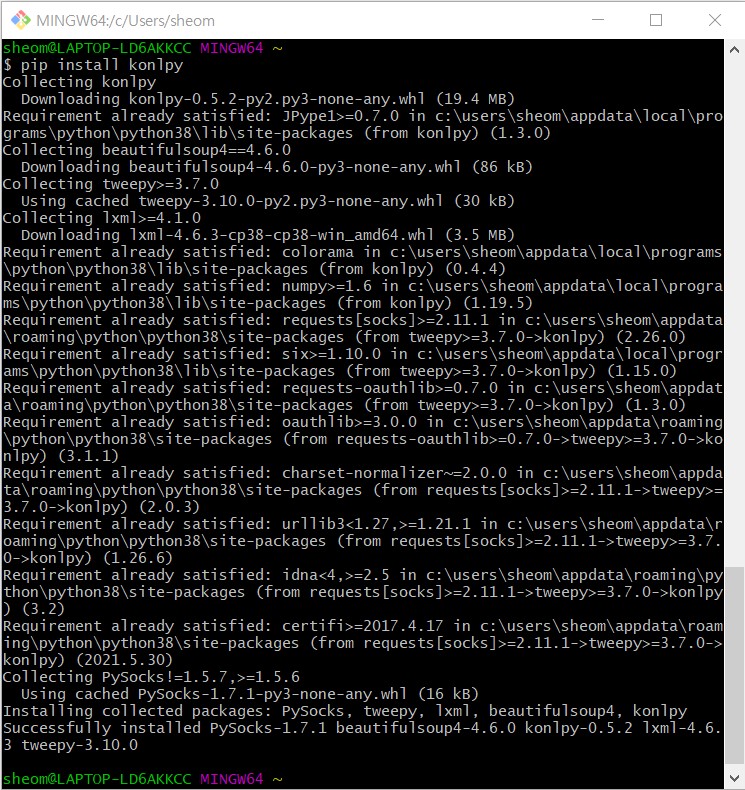
5. pip install konlpy
성공입니다!
이후 Mecab 설치 부분에서 막혀서 새벽 6시에 잠들게 되는데요...
결론은 eunjeon을 통해서 성공했습니다!
+ 다시 pip install eunjeon으로 해결하려고 했습니다. 그런데 해당 오류가 납니다.
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
----------------------------------------
ERROR: Command errored out with exit status 1: 'c:\users\sheom\appdata\local\programs\python\python38\python.exe
사이트로 들어가서 다운로드받았고 실행했더니 또 microsoft visual c++ build tools 에서는 다음과 같은 오류가 났습니다.
설치 패키지가 없거나 손상되었습니다
그래서 해결 방법을 찾다가, 다음 포스트를 발견하고 Visual Studio 를 다운로드 받았고,
[Windows] Python/npm 패키지 설치에 필요한 빌드 도구 설치하기 (tistory.com)
[Windows] Python/npm 패키지 설치에 필요한 빌드 도구 설치하기
모든 Python 패키지가 그런 것은 아닙니다만, 일부 Python 패키지를 설치하려고 하면 다음 메세지 중 하나가 붉은색으로 나타나면서 패키지의 설치가 중단될 때가 있습니다. npm 역시 마찬가지로, 두
pivox.tistory.com
용량을 너무 많이 차지하길래 저도 빌드 도구 하나만 선택하여 다운로드 받았습니다.
컴퓨터 재시작 하고, 다시 pip install eunjeon.... 또 에러!^^
c:\users\sheom\appdata\local\programs\python\python38\include\pyconfig.h(206): fatal error C1083: 포함 파일을 열 수 없습니다. 'basetsd.h': No such file or directory
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\\cl.exe' failed with exit status 2
또다시 삽질시작,, 하다가 다음 포스트 발견..
Running Cython in Windows x64 - fatal error C1083: Cannot open include file: 'basetsd.h': No such file or directory
I have been trying to install Cython for Python 2.7 on my Window 7 system. In particular, I prefer everything in 64 bits. (In case you wonder, I need Cython because Cython is one of the components ...
stackoverflow.com
용량아낀다고 다 제거하고 빌드도구만 다운로드받아서 그런거라고 하네용 windows 10 sdk도 다운로드받아줍니다..진짜개빡친다
그런데 또 에러 발생ㅋㅋ
LINK : fatal error LNK1158: 'rc.exe'을(를) 실행할 수 없습니다.
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\\link.exe' failed with exit status 1158
차분하게 구글링 해줍니다.
https://stackoverflow.com/a/47875022
Visual Studio can't build due to rc.exe
I've searched online and couldn't find anything that resembled to my issue. I created an empty C++ project and added a main.cpp with a return and I can't get it to build. Here is the message I rec...
stackoverflow.com
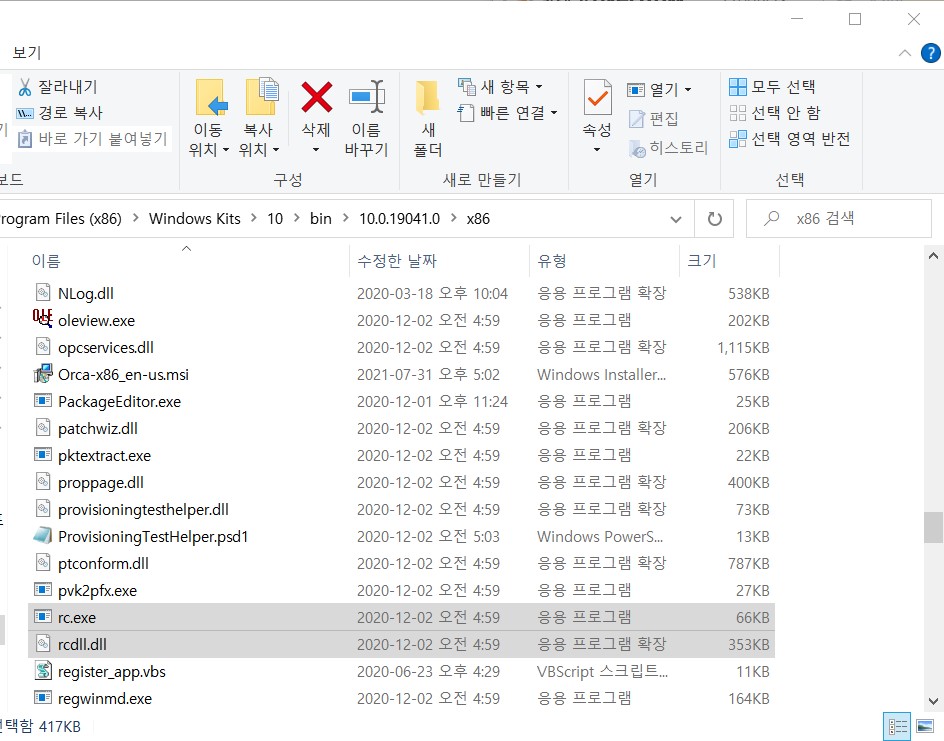
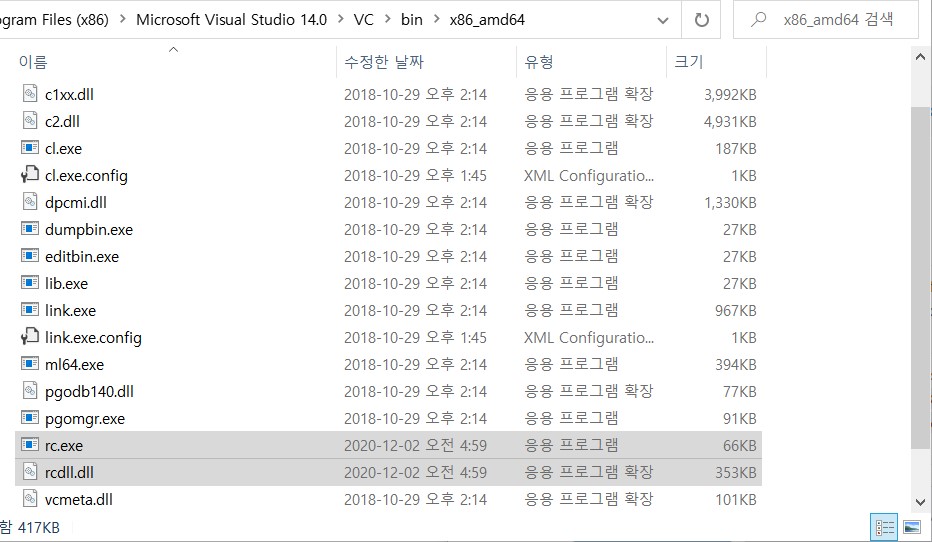
따라해줍니다. 파일 복사-> 붙여넣기.
그리고 또다시 pip install eunjeon...
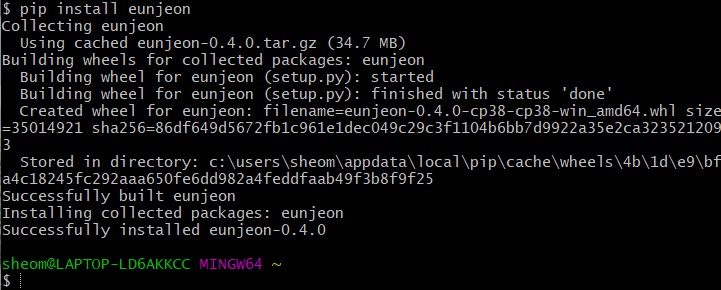
실화냐???????????????? Successfully installed 라는 문구를 너무 오랜만에 봐서 감격스러운 나;;
from eunjeon import Mecab
tagger = Mecab()
sentence = "언제나 현재에 집중할 수 있다면 행복할 것이다."
tagger.pos(sentence)
# [('언제나', 'MAG'), ('현재', 'NNG'), ('에', 'JKB'), ('집중', 'NNG'), ('할', 'XSV+ETM'), ('수', 'NNB'), ('있', 'VV'), ('다면', 'EC'), ('행복', 'NNG'), ('할', 'XSV+ETM'), ('것', 'NNB'), ('이', 'VCP'), ('다', 'EF'), ('.', 'SF')]
tagger.morphs(sentence) # 토큰화만
# ['언제나', '현재', '에', '집중', '할', '수', '있', '다면', '행복', '할', '것', '이', '다', '.']
tagger.nouns(sentence) # 형태소만 사용하고 싶을 때 조사 접속사 제거 가능
# ['현재', '집중', '수', '행복', '것']꺄아아악!!!
여러분. 존버는 성공합니다.
문장 토큰화
- 한국어 문장 토큰화 시에는 kss 라이브러리 사용
import kss
text = '진짜? 내일 뭐하지. 이렇게 애매모호한 문장도? 밥은 먹었어? 나는...'
print(kss.split_sentences(text)) # ['진짜? 내일 뭐하지.', '이렇게 애매모호한 문장도? 밥은 먹었어?', '나는...']
정규 표현식을 이용한 토큰화
from nltk.tokenize import RegexpTokenizer
sentence = '안녕하세요 ㅋㅋ 저는 자연어 처리(Natural Language Processing)를ㄹ!! 배우고 있습니다.'
tokenizer = RegexpTokenizer("[가-힣]+")
tokens = tokenizer.tokenize(sentence)
tokens # ['안녕하세요', '저는', '자연어', '처리', '를', '배우고', '있습니다']
tokenizer = RegexpTokenizer("[ㄱ-ㅎ]+", gaps= True)
tokens = tokenizer.tokenize(sentence)
tokens # ['안녕하세요 ', ' 저는 자연어 처리(Natural Language Processing)를', '!! 배우고 있습니다.']
케라스를 이용한 토큰화
from keras.preprocessing.text import text_to_word_sequence
sentence = '성공의 비결은 단 한 가지, 잘할 수 있는 일에 광적으로 집중하는 것이다.'
text_to_word_sequence(sentence) # ['성공의', '비결은', '단', '한', '가지', '잘할', '수', '있는', '일에', '광적으로', '집중하는', '것이다']TextBlob을 이용한 토큰화
from textblob import TextBlob
blob = TextBlob(sentence)
blob.words # WordList(['성공의', '비결은', '단', '한', '가지', '잘할', '수', '있는', '일에', '광적으로', '집중하는', '것
이다'])
Bag of Words (BoW)
# sklearn으로 BoW
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["Think like a man of action and act like man of thought."]
vector = CountVectorizer()
bow = vector.fit_transform(corpus) # 단어의 빈도수
print(bow.toarray()) # [[1 1 1 2 2 2 1 1]]
print(vector.vocabulary_) # 위의 벡터에 있어서 각각의 단어가 몇번째인지 {'think': 6, 'like': 3, 'man': 4, 'of': 5, 'action': 1, 'and': 2, 'act': 0, 'thought': 7}
vector = CountVectorizer(stop_words='english') # 위의 BoW와 동일하지만 stopword 만 제거
bow = vector.fit_transform(corpus)
print(bow.toarray()) # [[1 1 2 2 1 1]]
print(vector.vocabulary_) # {'think': 4, 'like': 2, 'man': 3, 'action': 1, 'act': 0, 'thought': 5}
corpus = ["평생 살 것처럼 꿈을 꾸어라. 그리고 내일 죽을 것처럼 오늘을 살아라."]
vector = CountVectorizer()
bow = vector.fit_transform(corpus) # 단어의 빈도수
print(bow.toarray()) # [[2 1 1 1 1 1 1 1 1]]
print(vector.vocabulary_) # {'평생': 8, '것처럼': 0, '꿈을': 3, '꾸어라': 2, '그리고': 1, '내일': 4, '죽을': 7, '오늘을': 6, '살아라': 5}
# Mecab 이용해서 Bow
import re
from eunjeon import Mecab
tagger = Mecab()
corpus = "평생 할 것처럼 꿈을 꾸어라. 그리고 내일 죽을 것처럼 오늘을 살아라."
tokens = tagger.morphs(re.sub("(\.)", "", corpus)) # .을 공백으로 대체, 토큰화
vocab = {}
bow = []
for tok in tokens:
if tok not in vocab.keys(): # 없으면 추가해라
vocab[tok] = len(vocab)
bow.insert(len(vocab)-1, 1)
else:
index = vocab.get(tok) # 있으면 key(단어) 에 해당되는 값에 1을 더해라
bow[index] = bow[index]+1
print(bow) # [1, 1, 2, 2, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1]
print(vocab) # {'평생': 0, '할': 1, '것': 2, '처럼': 3, '꿈': 4, '을': 5, '꾸': 6, '어라': 7, '그리고': 8, '내일': 9, '죽': 10, '오늘': 11, '살': 12, '아라': 13}
문서 단어 행렬 DTM
- 문서에 등장하는 여러 단어들의 빈도를 행렬로 표현
- 각 문서에 대한 BoW를 하나의 행렬로 표현한 것
# sklearn 으로 만들기
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["Think like a man of action and act like man of thought.",
"Try not to become a man of success but rather try to become a man of value.",
"Give me liberty, or give me death."]
vector = CountVectorizer(stop_words='english')
bow = vector.fit_transform(corpus)
print(bow.toarray())
# [[1 1 0 0 2 2 0 1 1 0 0]
# [0 0 0 0 0 2 1 0 0 2 1]
# [0 0 1 1 0 0 0 0 0 0 0]]
print(vector.vocabulary_)
# {'think': 7, 'like': 4, 'man': 5, 'action': 1, 'act': 0, 'thought': 8, 'try': 9, 'success': 6, 'value': 10, 'liberty': 3, 'death': 2}
# pandas 로 만들기
import pandas as pd
columns = []
for k, v in sorted(vector.vocabulary_.items(), key = lambda item:item[1]): # 람다(숫자 상으로) 두번째(위 딕셔너리에서 두번째는 숫자)
columns.append(k)
df = pd.DataFrame(bow.toarray(), columns=columns)
df
# act action death liberty like man success think thought try value
# 0 1 1 0 0 2 2 0 1 1 0 0
# 1 0 0 0 0 0 2 1 0 0 2 1
# 2 0 0 1 1 0 0 0 0 0 0 0
어휘 빈도-문서 역빈도 (TF-IDF) 분석 : sklearn TfidfVectorizer 사용
- 단순히 빈도 수가 높은 단어가 핵심어가 아닌, 특정 문서에서만 집중적으로 등장할 때 해당 단어가 문서의 주제를 잘 담고 있는 핵심어라고 가정
- 특정 문서에서 특정 단어가 많이 등장하고, 그 단어가 다른 문서에서 적게 등장할 때, 그 단어를 특정 문서의 핵심어로 간주
- 어휘 빈도 : 특정 문서에서 특정 단어가 많이 등장하는 것을 의미
- 역문서 빈도 : 다른 문서에서 등장하지 않는 단어 빈도
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english').fit(corpus)
print(tfidf.transform(corpus).toarray())
# [[0.311383 0.311383 0. 0. 0.62276601 0.4736296
# 0. 0.311383 0.311383 0. 0. ]
# [0. 0. 0. 0. 0. 0.52753275
# 0.34682109 0. 0. 0.69364217 0.34682109]
# [0. 0. 0.70710678 0.70710678 0. 0.
# 0. 0. 0. 0. 0. ]]
print(tfidf.vocabulary_)
# {'think': 7, 'like': 4, 'man': 5, 'action': 1, 'act': 0, 'thought': 8, 'try': 9, 'success': 6, 'value': 10, 'liberty': 3, 'death': 2}
# 보기 편하도록 pandas 이용해 DataFrame으로 변환
columns = []
for k, v in sorted(tfidf.vocabulary_.items(), key=lambda item:item[1]):
columns.append(k)
pd.DataFrame(tfidf.transform(corpus).toarray(), columns=columns)
# act action death liberty like ... success think thought try value
# 0 0.311383 0.311383 0.000000 0.000000 0.622766 ... 0.000000 0.311383 0.311383 0.000000 0.000000
# 1 0.000000 0.000000 0.000000 0.000000 0.000000 ... 0.346821 0.000000 0.000000 0.693642 0.346821
# 2 0.000000 0.000000 0.707107 0.707107 0.000000 ... 0.000000 0.000000 0.000000 0.000000 0.000000
'Computer > ML·DL·NLP' 카테고리의 다른 글
| [이수안컴퓨터연구소] 의미 연결망 분석 Semantic Network Analysis (0) | 2021.08.07 |
|---|---|
| [이수안컴퓨터연구소] 문서 분류 Document Classification (0) | 2021.08.07 |
| [이수안컴퓨터연구소] 군집 분석 Cluster Analysis (0) | 2021.08.04 |
| [이수안컴퓨터연구소] 키워드 분석 Keyword Analysis (0) | 2021.08.04 |
| [이수안컴퓨터연구소] 자연어 처리 Natural Language Processing 기초 1 (영어 NLP) (0) | 2021.07.28 |




댓글