https://www.youtube.com/watch?v=2e9wnwuAVv0&list=PL7ZVZgsnLwEEoHQAElEPg7l7T6nt25I3N
혹시 밑의 에러들로 검색해서 들어왔다면 밑의 접은글을 누르시면 됩니다..
ImportError: Keras requires TensorFlow 2.2 or higher. Install TensorFlow via `pip install tensorflow`
ERROR: Could not install packages due to an EnvironmentError: [WinError 5] 액세스가 거부되었습니다
File "C:\Users\sheom\anaconda3\lib\sqlite3\dbapi2.py", line 27, in <module>
from _sqlite3 import *
ImportError: DLL load failed while importing _sqlite3: 지정된 모듈을 찾을 수 없습니다.
AttributeError: partially initialized module 'nltk' has no attribute 'data' (most likely due to a circular import)
정규표현식, Regular Expression, 토큰화, Tokenization, PoS 태깅, Parts of Speech Tagging, 불용어 제거, Stopwords, 어간, Stemming, 표제어, Lemmatization, 개체명 인식, Named Entities Recognition, Bag of Words, BoW, DTM, Document Term Matrix, TF-IDF, Term Frequency-Inverse Document Frequency
1. 정규표현식 (regular expression): 특정 문자들을 편리하게 지정하고 추가, 삭제 가능. 데이터 전처리에서 많이 사용됨.
파이썬에서의 정규 표현식: re 패키지 사용!
| 특수문자 | 설명 |
| . | 앞의 문자 1개 표현 |
| ? | 문자 1개를 표현하지만, 존재할 수도, 존재하지 않을 수도 있음 (0개 또는 1개) |
| * | 앞의 문자 0개 이상 |
| + | 앞의 문자 1개 이상 |
| ^ | 뒤의 문자로 문자열이 시작 |
| \$ | 앞의 문자로 문자열이 끝남 |
| \[n\] | n번만큼 반복 |
| \[n1, n2\] | n1 이상, n2 이하만큼 반복, n2를 지정하지 않으면 n1이상만 반복 |
| \[abc\] | 안에 문자들 중 한 개의 문자와 매치, a-z 처럼 범위도 지정 가능 |
| \[^a\] | 해당 문자를 제외하고 매치 |
| a|b | a 또는 b를 나타냄 |
정규 표현식에 자주 사용하는 역슬래시(\)를 이용한 문자 규칙
| 문자 | 설명 |
| \\ | 역슬래시 자체를 의미 |
| \d | 모든 숫자를 의미, [0-9]와 동일 |
| \D | 숫자를 제외한 모든 문자를 의미, [^0-9]를 의미 |
| \s | 공백을 의미. [\t\n\r\f\v]와 동일 |
| \S | 공백을 제외한 모든 문자를 의미. [^\t\n\r\f\v]와 동일 |
| \w | 문자와 숫자를 의미, [a-zA-Z0-9]와 동일 |
| \W | 문자와 숫자를 제외한 다른 문자를 의미, [^a-zA-Z0-9]와 동일 |
import re # re 패키지 가져오기
check = 'ab.' # 정규표현식 문자열
# 1. match
print(re.match(check, 'abc')) # matched
print(re.match(check, 'c')) # None
print(re.match(check, 'ab')) # None
# 2. compile : 정규식을 여러 번 사용하고 싶을 때 사용. 훨씬 효율적임.
# 이 경우 re가 아닌, 컴파일한 객체 이름을 통해 사용해야 함
import time
# compile 사용 안했을 때 시간 계산
normal_s_time = time.time()
r = 'ab.'
for i in range(1000):
re.match(check, 'abc')
print('일반 사용시 소요 시간:', time.time() - normal_s_time) # 26.337 초
# compile 사용했을 때 시간 계산
compile_s_time = time.time()
r = re.compile('ab.')
for i in range(1000):
r.match(check)
print('컴파일 사용시 소요 시간:', time.time() - compile_s_time) # 0.467 초
# 3. search : match와는 다르게, search는 문자열의 전체를 검사
check = 'ab?'
print(re.search('a', check)) # matched 'a'
print(re.match('kkkab', check)) # None
print(re.search('kkkab', check)) # None
print(re.match('ab', check)) # matched 'ab'
# 4. split : 정규표현식에 해당하는 문자열을 기준으로 문자열을 나눔
r = re.compile(' ')
print(r.split('abc abbc abcbab')) # ['abc', 'abbc', 'abcbab']
r = re.compile('c')
print(r.split('abc abbc abcbab')) # ['ab', ' abb', ' ab', 'bab']
r = re.compile('[1-9]')
print(r.split('sdu4 xdb2 5idf 3a')) # ['sdu', ' xdb', ' ', 'idf ', 'a']
# sub : 정규 표현식과 일치하는 부분을 다른 문자열로 교체
print(re.sub('[a-z]', 'abcdefg', '1')) # 1
print(re.sub('[^a-z]', 'abc defg', '1')) # abc defg
# findall : 컴파일한 정규 표현식을 이용해 정규 표현식과 맞는 모든 문자(열)을 리스트로 반환
print(re.findall('[\d]', '1ab 2cd 3ef 4g')) # 숫자: ['1', '2', '3', '4']
print(re.findall('[\W]', '!abcd@@#')) # 특수문자: ['!', '@', '@', '#']
# finditer : 컴파일한 정규 표현식과 맞는 모든 문자(열)을 iterator 객체로 반환
# iterator 객체를 이용하면 생성된 객체를 하나씩 자동으로 가져올 수 있어 처리가 간편함
iter1 = re.finditer('[\d]', '1ab 2cd 3ef 4g')
print(iter1)
for i in iter1:
print(i)
iter2 = re.finditer('[\W]', '!abc@@#')
print(iter2)
for i in iter2:
print(i)
2. 토큰화 Tokenization
* 주의할 점!
1) 특수문자에 대한 처리
- 단어에 일반적으로 사용되는 알파벳, 숫자와는 다르게 특수문자는 별도의 처리가 필요
- 일괄적으로 단어의 특수문자를 제거하는 방법도 있지만 특수문자가 단어에 특별한 의미를 가질 때 이를 학습에 반영시키지 못할 수도 있음
- 특수문자에 대한 일괄적인 제거보다는, 데이터의 특성을 파악하고, 처리를 하는 것이 중요
2) 특정 단어에 대한 토큰 분리 방법
- 한 단어지만 토큰으로 분리할 때 판단되는 문자들로 이루어진 we're, United Kingdom 등의 단어는 어떻게 분리해야 할지 선택이 필요
- we're은 한 단어이나 분리해도 단어의 의미에 별 영향을 끼치진 않지만 United Kingdom은 두 단어가 모여 특정 의미를 가리켜 분리해선 안됨
- 사용자가 단어의 특성을 고려해 토큰을 분리하는 것이 학습에 유리
단어 토큰화: 파이썬 내장 함수인 split을 활용. 공백을 기준으로 단어를 분리
토큰화는 nltk 패키지의 tokenize 모듈을 사용해 손쉽게 구현 가능. 단어 토큰화는 word_tokenize() 함수를 사용해 구현 가능
문장 토큰화는 줄바꿈 문자('\n')를 기준으로 문장을 분리, 문장 토큰화는 sent_tokenize 이용해 가능.
문장 토큰화에서는 온점(.)의 처리를 위해 이진 분류기를 사용할 수도 있음. 온점은 문장과 문장을 구분해줄 수도, 문장에 포함된 단어를 구성할 수도 있기 때문에 이를 이진 분류기로 분류해 더욱 좋은 토큰화를 구현할 수 도 있음.
정규표현식을 이용한 토큰화: 토큰화 기능을 직접 구현할 수도 있지만 정규 표현식을 이용해 간단하게 구현할 수도 있음. nltk 패키지는 정규 표현식을 사용하는 토큰화 도구인 RegexpTokenizer를 제공. 이 정규 표현식에 맞는 토큰만 출력됨
sentence = 'Time is gold'
sentence.split() # ['Time', 'is', 'gold']
tokens = [x for x in sentence.split(' ')]
tokens # ['Time', 'is', 'gold']
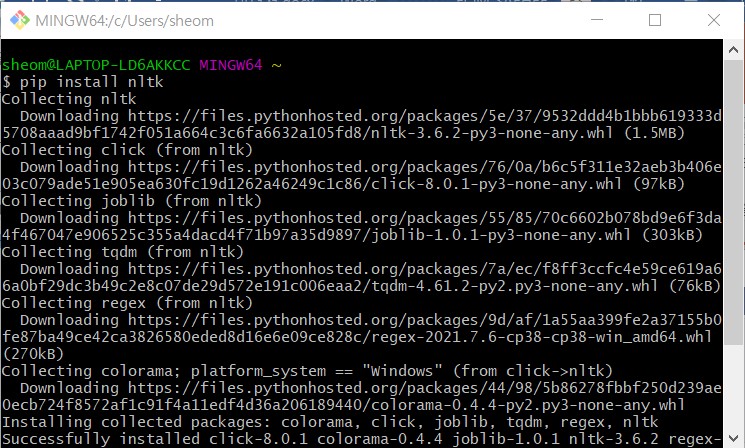
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
tokens = word_tokenize(sentence)
tokens # ['Time', 'is', 'gold']
sentences = 'The world is a beautiful book.\nBut of little use to him who cannot read it'
print(sentences)
tokens = [x for x in sentences.split('\n')]
tokens # ['The world is a beautiful book.', 'But of little use to him who cannot
read it']
from nltk.tokenize import sent_tokenize
tokens = sent_tokenize(sentences)
tokens # ['The world is a beautiful book.', 'But of little use to him who cannot
read it']
from nltk.tokenize import RegexpTokenizer
sentence = 'When there\'s a will, there\'s a way'
tokenizer = RegexpTokenizer("[\w]+") # 문자와 숫자가 최소 1개 이상. 첫번째 인자는 토큰을 정의하는데 사용된다.
tokens = tokenizer.tokenize(sentence)
tokens # ['When', 'there', 's', 'a', 'will', 'there', 's', 'a', 'way']
tokenizer = RegexpTokenizer("[\s]+", gaps = True) # gaps = True 라는 것은, 첫번째 인자가 갭을 정의하는데 사용된다는 뜻
tokens = tokenizer # ['When', "there's", 'a', 'will,', "there's", 'a', 'way']케라스를 이용한 토큰화
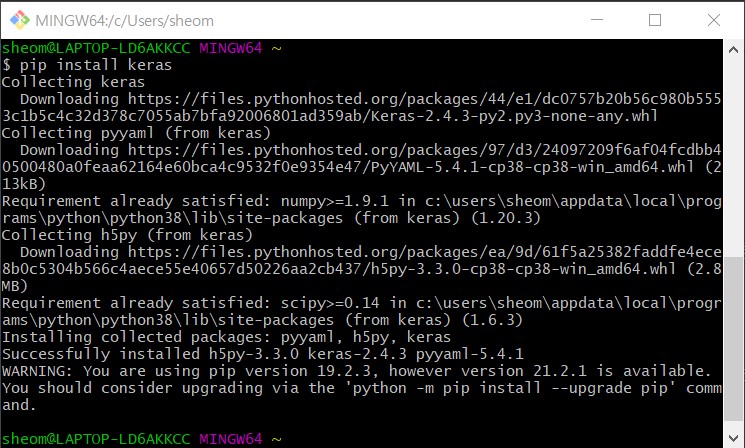
keras 설치 후 파이썬에서 from keras.processing.text import text_to_word_sequence 실행했더니,
ImportError: Keras requires TensorFlow 2.2 or higher. Install TensorFlow via `pip install tensorflow`
라고 떠서 pip install tensorflow로 다시 설치했다. 그런데 또 오류!

ERROR: Could not install packages due to an EnvironmentError: [WinError 5] 액세스가 거부되었습니다
그래서 제시해주는 대로 또 pip install --user tensorflow 로 설치.
이후 다시 VSCode에서 keras 어쩌구저쩌구 실행해봤는데 똑같이 텐서플로우 설치하라네? 혹시 셸에서 설치한게 반영이 안됐나 싶어서 코드 저장 후에 다시 VSCode 실행했더니 이번엔 nltk가 없대,,
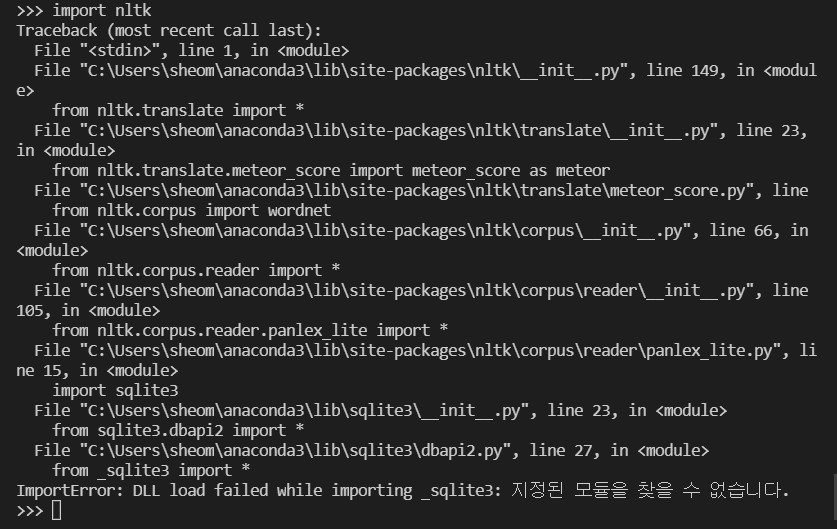
File "C:\Users\sheom\anaconda3\lib\sqlite3\dbapi2.py", line 27, in <module>
from _sqlite3 import *
ImportError: DLL load failed while importing _sqlite3: 지정된 모듈을 찾을 수 없습니다.
그래서 해당 에러메세지 구글링하다가 본 한국어 블로그,, (영어 자신있지만 기술적인 내용 읽는건 넘무 어려워요)
ImportError: DLL load fai.. : 네이버블로그 (naver.com)
ImportError: DLL load failed while importing _sqlite3: 지정된 모듈을 찾을 수 없습니다.
https://stackoverflow.com/questions/54876404/unable-to-import-sqlite3-using-anaconda-python https://...
blog.naver.com
시키는대로 해보았다. 나는 64bit니까 맞는 버전 다운로드
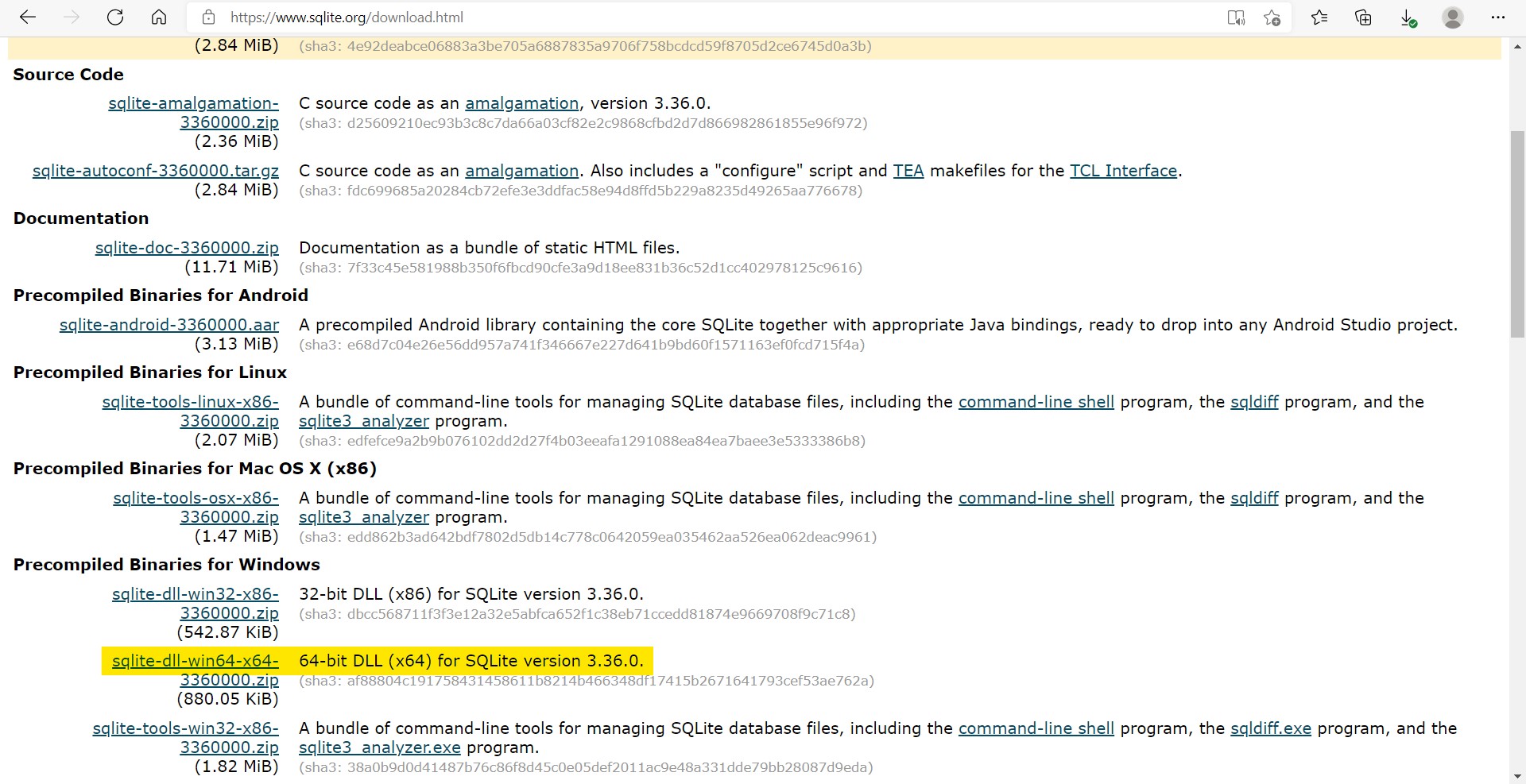
압축풀고, dll 파일만 'C:\Users\user\anaconda3\DLLs' 여기에 넣는당
그리고 다시 import nltk 시도..
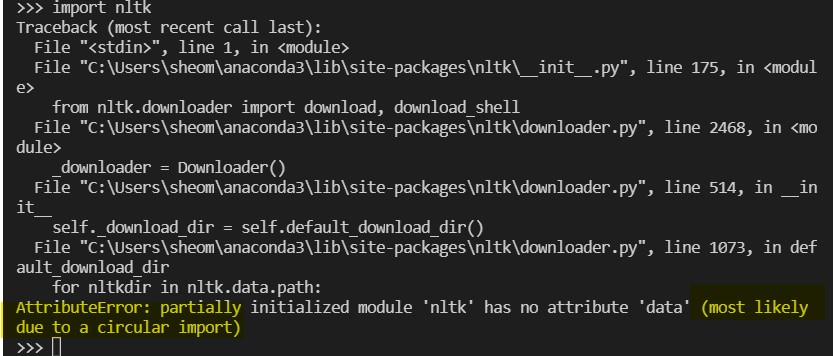
AttributeError: partially initialized module 'nltk' has no attribute 'data' (most likely due to a circular import)
진짜 whyrano.. 마지막 하이라이트 친 부분에서 힌트를 얻어 구글링해봤는데, nltk.py 라는 파이썬 파일을 만들면 이런 오류가 난다고 한다. 근데 난 만든 적 없음. recursive 하게 검색해봤는데도 안뜸. 고로 most likely에 해당되지 않나부다.. 했고..
사실 나는 anaconda를 설치한 기억도 없었는데 (작년에 수업 들으면서 시키는대로 했기때문) 분명 나는 콘솔창에서 nltk를 다운받았는데 왜 자꾸 아나콘다가 뜨는거지..? 싶었다. 아나콘다가 뭔지도 몰랐는데ㅋㅋㅋㅋ
찾아보니 아나콘다가 파이썬 인터프레터 및 여러가지 패키지를 같이 묶어둔 거라고 한다. 굳이굳이 다 따로 다운로드 받을 수도 있겠지만 나중에 오류가 날까봐 그런다는데 일단 널 좀 삭제해야겠어..
Uninstalling Anaconda — Anaconda documentation
Uninstalling Anaconda — Anaconda documentation
Uninstalling Anaconda To uninstall Anaconda, you can do a simple remove of the program. This will leave a few files behind, which for most users is just fine. See Option A. If you also want to remove all traces of the configuration files and directories fr
docs.anaconda.com
여기서 보고 아나콘다 삭제했고, 결론적으로 문제 해결. nltk도 잘 작동한다. 다만 VScode 처음 실행할 때 인터프리터 선택안돼서 왜이래?! 광분했다... 진정하고 오류 메세지나 읽어보자.. 인터프리터 선택하면 됩니다
import keras
from keras.preprocessing.text import text_to_word_sequence
sentence = "Where there\'s a will, there\'s a way"
text_to_word_sequence(sentence) # ['where', "there's", 'a', 'will', "there's", 'a', 'way']TextBlob을 이용한 토큰화 (이건 굳이 실습해보지 않았다)
기타 토크나이저: WhiteSpaceTokenizer, WordPunkTokenizer, MWETokenizer, TweetTokenizer
n-gram 추출
- n-gram은 n 개의 어절이나 음절을 연쇄적으로 분류해 그 빈도를 분석
- n = 1 일 때는 unigram, 2 일 때는 bigram, 3일 때는 trigram
from nltk import ngrams
sentence = 'There is no royal road to learning'
bigram = list(ngrams(sentence.split(), 2))
print(bigram) # [('There', 'is'), ('is', 'no'), ('no', 'royal'), ('royal', 'road'), ('road', 'to'), ('to', 'learning')]
trigram = list(ngrams(sentence.split(), 3))
print(trigram) # [('There', 'is', 'no'), ('is', 'no', 'royal'), ('no', 'royal', 'road'),
('royal', 'road', 'to'), ('road', 'to', 'learning')]PoS(Parts of Speech) 태깅
- PoS 란 품사를 의미하고, PoS 태깅은 문장 내에서 단어에 해당하는 각 품사를 태깅
import nltk
nltk.download('punkt')
from nltk import word_tokenize
words = word_tokenize("Think like man of action and act like man of thought.")
words # ['Think', 'like', 'man', 'of', 'action', 'and', 'act', 'like', 'man', 'of', 'thought', '.']
nltk.download('averaged_perceptron_tagger')
nltk.pos_tag(words)
# [('Think', 'VBP'), ('like', 'IN'), ('man', 'NN'), ('of', 'IN'), ('action', 'NN'), ('and', 'CC'), ('act', 'NN'), ('like', 'IN'), ('man', 'NN'), ('of', 'IN'), ('thought', 'NN'), ('.', '.')]
nltk.pos_tag(word_tokenize("A rolling stone gathers no moss."))
# [('A', 'DT'), ('rolling', 'VBG'), ('stone', 'NN'), ('gathers', 'NNS'), ('no', 'DT'), ('moss', 'NN'), ('.', '.')]
불용어 (stopword) 제거
- 영어의 전치사, 한국어의 조사 등은 분석에 필요하지 않은 경우가 많음.
- 길이가 짧은 단어, 등장 빈도 수가 적은 단어들도 분석에 큰 영향을 주지 않음.
- 일반적으로 사용되는 도구들은 해당 단어들을 제거해주지만 완벽하게 제거되지는 않음
- 사용자가 불용어 사전을 만들어 해당 단어들을 제거하는 것이 좋음
- 도구들이 걸러주지 않는 전치사, 조사 등을 불용어 사전을 만들어 불필요한 단어들을 제거
# 직접 불용어 사전 만들기
stop_words = "on in the"
stop_words = stop_words.split(" ")
stop_words
sentence = "singer on the stage"
sentence = sentence.split()
nouns = []
for noun in sentence:
if noun not in stop_words:
nouns.append(noun)
nouns # ['singer', 'stage']nltk 패키지에 불용어 리스트 사용
from nltk import word_tokenize
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
# ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how',
'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn',
"hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
s = "If you do not walk today, you will have to run tomorrow."
words = word_tokenize(s)
print(words)
no_stopwords = []
for w in words :
if w not in stop_words:
no_stopwords.append(w)
print(no_stopwords) # ['If', 'walk', 'today', ',', 'run', 'tomorrow', '.']
철자 교정 : autocorrect
- 텍스트에 오탈자가 존재하는 경우가 있음
- 철자 순서가 바뀌거나 / 철자가 틀리는 경우
- 사람이 적절한 추정을 통해 이해하는데는 문제가 없지만, 컴퓨터는 이러한 단어를 그대로 받아들여 처리가 필요
- 철자 교정 알고리즘은 이미 개발되어 워드 프로세서나 다양한 서비스에서 많이 적용됨
from autocorrect import Speller
spell = Speller('en')
print(spell('peoplle')) # people
print(spell('peope')) # people
print(spell('peopae')) # people
s = word_tokenize("Earlly biird catchess the wormm.")
print(s)
ss = ' '.join([spell(s) for s in s])
print(ss) # Early bird catches the worm .
언어의 단수화와 복수화 (textblob 실습은 생략하,, 려고 했으나 textblob을 활용한 방법밖에 없어 결국 설치함)
Installation — TextBlob 0.16.0 documentation
Installation — TextBlob 0.16.0 documentation
Migrating from older versions (<=0.7.1) As of TextBlob 0.8.0, TextBlob’s core package was renamed to textblob, whereas earlier versions used a package called text. Therefore, migrating to newer versions should be as simple as rewriting your imports, like
textblob.readthedocs.io
$ pip install -U textblob
$ python -m textblob.download_corpora 이렇게 두 개 명령어 실행하여 다운로드 받음
from textblob import TextBlob
words = 'apples bananas oranges'
tb = TextBlob(words)
print(tb.words)
print(tb.words.singularize())
words = 'car train airplane'
tb = TextBlob(words) # ['apple', 'banana', 'orange']
print(tb.words)
print(tb.words.pluralize()) # ['cars', 'trains', 'airplanes']
어간 추출 (stemming)
import nltk
stemmer = nltk.stem.PorterStemmer()
stemmer.stem('application') # 'applic'
stemmer.stem('beginning') # 'begin'
stemmer.stem('catches') # 'catch'
stemmer.stem('education') # 'educ'
표제어 추출 (lemmatization)
impork nltk
nltk.download('wordnet')
from nltk.stem.wordnet import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('application') # application
lemmatizer.lemmatize('beginning') # beginning
lemmatizer.lemmatize('catches') # catch
lemmatizer.lemmatize('education') # education
개체명 인식 (Named Entity Recognition)
import nltk
from nltk import word_tokenize
nltk.download('maxent_ne_chunker')
nltk.download('words')
s = "Rome was not built in a day"
print(s)
tags = nltk.pos_tag(word_tokenize(s))
print(tags) # [('Rome', 'NNP'), ('was', 'VBD'), ('not', 'RB'), ('built', 'VBN'), ('in', 'IN'), ('a', 'DT'), ('day', 'NN')]
entities = nltk.ne_chunk(tags, binary=True)
print(entities) # (S (NE Rome/NNP) was/VBD not/RB built/VBN in/IN a/DT day/NN)잘 보면 named entity 인 Rome 에만 NE 라고 붙는 것을 확인할 수 있음
단어 중의성 (lexical ambiguity)
import nltk
from nltk.wsd import lesk
s = "I saw bats."
print(word_tokenize(s))
print(lesk(word_tokenize(s), 'saw')) # Synset('saw.v.01')
print(lesk(word_tokenize(s), 'bats')) # Synset('squash_racket.n.01')Synset 안에 들어가는 의미가 중의성을 갖는 의미 중에서 가장 말이 되는 경우임.
따라서 위의 문장에서 saw는 '톱(질을 하다)'이 아니라 '보았다'라는 의미, 'bats'는 '박쥐'가 아니라 '야구방망이'로 보아야 한다.
'Computer > ML·DL·NLP' 카테고리의 다른 글
| [이수안컴퓨터연구소] 의미 연결망 분석 Semantic Network Analysis (0) | 2021.08.07 |
|---|---|
| [이수안컴퓨터연구소] 문서 분류 Document Classification (0) | 2021.08.07 |
| [이수안컴퓨터연구소] 군집 분석 Cluster Analysis (0) | 2021.08.04 |
| [이수안컴퓨터연구소] 키워드 분석 Keyword Analysis (0) | 2021.08.04 |
| [이수안컴퓨터연구소] 자연어 처리 Natural Language Processing 기초 2 한국어 NLP (Feat. Windows에서 Mecab 사용하기!) (0) | 2021.07.28 |




댓글