트위터 장악한 '달리 미니(DALL-E mini)'가 뭐길래? < 포커스 < 기사본문 - AI타임스 (aitimes.com)
트위터 장악한 '달리 미니(DALL-E mini)'가 뭐길래? - AI타임스
트위터(Twitter)에서 다소 기이한 사진을 발견했다면 아마도 이미지 생성기 달리 미니(DALL-E mini)를 사용하는 것일 것이다. DALL-E mini는 인공 지능을 사용해 사용자가 입력한 프롬프트를 기반으로 이
www.aitimes.com
최신 바이러스성 AI 도구, 트위터에 등장
오픈AI의 DALL-E mini 버전을 대중에 공개
텍스트 프롬프트를 초현실적 이미지로 생성
트위터(Twitter)에서 다소 기이한 사진을 발견했다면 아마도 이미지 생성기 달리 미니(DALL-E mini)를 사용하는 것일 것이다. DALL-E mini는 인공 지능을 사용해 사용자가 입력한 프롬프트를 기반으로 이미지를 생성하는 AI 모델이다. 기본적으로 사진 격자 형식으로 가장 기이한 개념이나 시나리오를 시각화할 수 있다. 기계 학습 엔지니어인 보리스 데이마(Boris Dayma)가 구글과 AI 커뮤니티인 허깅 페이스(Hugging Face)가 개최한 대회의 일환으로 2021년 7월에 GPT-3을 기반으로 만들어졌다.
오잉?! GPT-3는 언어모델인데 이미지 생성기의 기반이 된다니 신기하다. 워낙 NLP와 vision 분야의 모델이 서로서로 갖다 쓴다지만 GPT-3는 pre trained language model인데?
궁금해서 OpenAI의 공홈에서 DALL-E 관련 문서를 찾아보았다. (이 기사는 DALL-E mini에 대한 글이지만, 결국 DALL-E가 원본이라고 볼 수 있기에 해당 문서를 참고하였다)
DALL·E: Creating Images from Text (openai.com)
DALL·E: Creating Images from Text
We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
openai.com
먼저 Image GPT에 대한 소개가 필요하다. Image GPT는 1차원 sequence를 학습하는 트랜스포머 기반 언어 모델들을 2차원 sequence인 이미지를 학습하도록 변형한 것. 이러한 트랜스포머의 특성을 'domain agnostic'이라고 한다. 이러한 특성이 있기에 비지도학습으로도 비슷한 이미지를 생성해낼 수 있다고 한다! 추가적으로 이러한 Language to Image의 아이디어의 바탕에는 'Analysis by synthesis'라는 아이디어가 있는데, 이는 생성 모델들이 카테고리를 더 잘 인식할 수 있다는 것이다. 따라서 카테고리를 인식하는 것이 필요한 분류에서 더 뛰어난 성능을 보여줄 수 있다고 한다. 나는 오늘 Image GPT가 있는지도 처음 알았다! 출처 : [Image GPT (openai.com)](https://openai.com/blog/image-gpt/)
이제 DALL-E에 대한 설명을 간단하게 해보자면..
- GPT-3가 언어생성모델의 가능성을 보여주었고, Image GPT는 NN기반 이미지 생성모델의 가능성을 보여주었다. 이러한 가능성을 바탕으로 언어에서 이미지를 생성하는 모델을 만들어낼 수 있었다.
- 일단 DALL-E도 트랜스포머 기반 언어 모델이다 (!!) 텍스트 & 이미지를 하나의 스트림으로 받아, 연쇄적으로 데이터를 학습하기에 (이전의 토큰으로 이후의 토큰 생성) 아주 조그마한 이미지 조각을 주더라도 이를 기반으로, 주어진 텍스트와 호환되도록 더 큰 이미지를 완성할 수 있게 한다.
- DALL-E는 decoder-only 트랜스포머 모델로, 언어는 256개 토큰 / 이미지는 1024개 토큰으로 이루어진 데이터들로 학습한다. 64개의 self-attention layer에 있는 attention mask는 각각의 이미지 토큰이 모든 언어 토큰을 참고하도록 한다.
라고 하는데 이 이상으로는 너무 어려워서 이해하기가 힘들다. ㅜㅜ 어텐션 모델과 트랜스포머 모델을 이론적으로만 이해하고 있어서 그런지 추가적인 학습이 필요할 것 같다.
오픈AI에는 세 가지 버전의 프로그램이 있다. 허깅 페이스에서 제공되는 DALL-E mini는 가장 우습고 가장 상상력이 풍부한 이미지를 생성하기 때문에 인기 있는 버전이다. DALL-E는 좀 더 정교하기 때문에 이미지가 훨씬 더 사실적이고 DALL-E 2는 DALL-E의 업그레이드 및 개선된 버전이다.
[관련기사]오픈AI, 텍스트를 고해상도 이미지로 생성하는 AI 시스템 ‘DALL-E 2’ 개발
오픈AI, 텍스트를 고해상도 이미지로 생성하는 AI 시스템 ‘DALL-E 2’ 개발 - AI타임스
미국의 인공지능 연구소 오픈AI(OpenAI)가 보고 싶은 것을 텍스트로 설명하면 디지털 이미지로 생성해 주는 AI 시스템을 만들었다고 최근 자사 블로그를 통해 발표했다. 이 시스템은 고해상도의 이
www.aitimes.com
DALL·E mini는 구글의 TPU Research Cloud에 의해 구동되며 구글이 지난달 출시한 Imagen과 유사하게 이미지를 생성하는 AI 모델이지만 대중이 접근할 수 있다는 점만 다를 뿐이다.
[관련기사]구글, ‘DALL-E 2’와 경쟁하는 ‘Imagen’ 발표
구글, ‘DALL-E 2’와 경쟁하는 ‘Imagen’ 발표 - AI타임스
구글이 텍스트 입력을 기반으로 이미지를 생성할 수 있는 새로운 인공지능(AI) 시스템을 선보였다. 구글은 \'전례 없는 수준의 사실적 묘사와 깊은 수준의 언어 이해\'를 통해 사실적인 이미지를
www.aitimes.com
가장 우습고 상상력이 풍부한 이미지를 만들어내서 인기가 좋다니ㅋㅋㅋ 생각지 못한 부분인데 생각해보니 생성 모델 특성상 그럴 수밖에 없을 것 같다는 생각이 든다. 사실 언어 생성 모델도 비슷할텐데, 예전에 카카오톡에서 서비스되던 '심심이'도 보통 사람과 소통할 때는 느끼지 못하는 통통 튀는 답변 (달리 말하자면 맥락을 읽지 못해 우스운 답변)을 접할 수 있기 때문에 인기가 많았던 것 같다.
근데 생각난 김에 검색해보니 심심이 웹페이지 UI가 굉장히 세련됐다...! 내 기억 속 심심이는 그 시절 구렸던 카카오톡 UI에 맞춰 촌스러웠던 것 같은데.. ㅋㅋㅋㅋ 2002년에 출시된 (생각보다 굉장히 오래됐다!) 세계 최초의 대중적인 일상대화 챗봇이고, 현재 81개 언어로 서비스되고 있다고 한다. 놀라운 점은 네이버 클로바 AI스피커가 있다면 '심심이 시작해줘'라고 했을 때 심심이가 실행된다는 것! 다음에 클로바 앱에서 한번 실행해봐야겠다 ㅋㅋ
심심이
심심할 때, 외로울 때, 대화가 필요한 모든 순간에 심심이와 대화를 시작해보세요. 일상대화, 감성대화 인공지능 챗봇 심심이입니다.
www.simsimi.com
구글의 TPU(Tensor Processing Unit) 에 대해서는 최근에 알게 되었는데, CPU / GPU보다 딥러닝에 더 최적화된 프로세싱 유닛(?)이라고 들었다. 딥러닝에 최적화되었기 때문에 CPU나 GPU를 사용할 때보다 훨씬 학습/테스트 시간이 단축된다고 알고 있었다. 더 자세히 찾아보니 2016년에 구글에서 소개한 하드웨어이고, 알파고도 TPU 기반이라고 한다!
TPU Research Cloud - About
Machine learning researchers around the world have done amazing things with the limited computational resources they currently have available. We'd like to empower researchers from many different backgrounds to think even bigger and tackle exciting new cha
sites.research.google
DALL-E mini는 누구나 프롬프트를 입력하고 ‘실행(Run)’ 버튼을 누를 수 있다. 하지만 종종 트래픽이 많아 대한 오류 메시지가 표시되고 다시 시도해야 할 수도 있다. DALL·E mini는 9개의 이미지가 포함된 3x3 격자 형태로 결과를 내보낸다. 그것들 중 하나를 클릭하여 더 크게 만들고 마우스 오른쪽 버튼을 클릭하거나 길게 탭하여 저장할 수 있다. 결과에 만족하지 않으면 실행을 다시 클릭해 동일한 프롬프트로 다른 요청을 할 수 있다.
웹사이트에 있는 이 도구에 대한 메모에는 "인터넷에서 필터링되지 않은 데이터을 학습해 사회적 편견을 강화하거나 악화시키는 데 사용될 수 있다”고 나와 있다. DALL·E mini를 직접 사용해보고 싶은 사람들은 여기에서 찾을 수 있다.
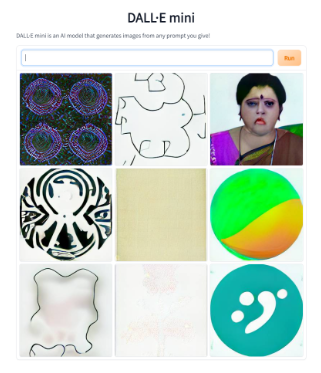
그러나 DALL·E mini는 개념은 잘 묘사하지만 사람의 얼굴과 관련된 부분에서 부분적으로 선명도 낮은 이미지를 생성한다. 데이마는 모델이 학습하는 과정이며 시간이 지남에 따라 개선될 수 있다고 말한다.
이 AI 생성기가 더 강력해질수록 더 명확하고 구체적인 결과로 미래에 더 유용할 것이다. 우리는 그것이 너무 강력해져서 세상을 지배하지 않기를 바랄 뿐이다.

'etc > IT 뉴스' 카테고리의 다른 글
| [221012] 메타-MS, 메타버스 '경쟁'보다 '공존' 선택 (1) | 2022.10.13 |
|---|---|
| [220502] “무엇이든 물어봐”...딥마인드, 소량의 데이터 만으로 학습하는 시각 언어 모델 공개 (0) | 2022.06.19 |
| [220506] 메타, 언어 모델 OPT-175B 무료 공개 (0) | 2022.05.10 |
| [211129] 네이버 커넥트재단, 연구학습용 데이터 공개...비영리 목적으로 활용 가능 (0) | 2022.01.05 |
| [211110] “AI 윤리, 원칙은 그만 만들고 기술적 접근법 마련해야” (0) | 2022.01.05 |




댓글