네이버, 초거대 AI 후속 연구 공개...영어·이미지까지 영역 확장 중 < 테크 < 기사본문 - AI타임스 (aitimes.com)
네이버, 초거대 AI 후속 연구 공개...영어·이미지까지 영역 확장 중 - AI타임스
네이버가 자사 초거대 인공지능(AI) 하이퍼클로바 최초 공개 이후 진행한 후속 연구 내용을 공개했다.한국어-영어 다국어 모델부터 이미지와 텍스트를 함께 다루는 멀티모달 모델, 규모가 큰 언
www.aitimes.com
- 네이버 개발자 컨퍼런스 'DEVIEW 2021' 내 하이퍼클로바 발표 내용
- 한국어-영어 다국어 모델, 이미지-텍스트 멀티모달 모델로 영역 확장
- 초거대 언어모델 평가 기술도 개발 중...모델 배포 위한 필수 관문

네이버가 자사 초거대 인공지능(AI) 하이퍼클로바 최초 공개 이후 진행한 후속 연구 내용을 공개했다.
한국어-영어 다국어 모델부터 이미지와 텍스트를 함께 다루는 멀티모달 모델, 규모가 큰 언어모델을 자동 평가하는 기술까지 크게 3가지 연구 주제가 핵심이다.
네이버가 24일부터 26일까지 진행하는 자체 개발자 컨퍼런스 'DEVIEW 2021'에는 하이퍼클로바 논문 제1저자로 참여한 다수 연구원들이 발표자로 나서 최근 연구 내용을 소개했다.
멀티 모달(Multi Modal) 딥러닝 (tistory.com)
멀티 모달(Multi Modal) 딥러닝
멀티 모달(Multi Modal) 멀티 모달은 여러 가지 형태와 의미로 컴퓨터와 대화하는 환경을 의미한다. 멀티 모달에서 모달은 모달리티(Modality)를 의미하는데 모달리티는 인터랙션 과정에서 사용되는
ohs-o.tistory.com
- 멀티 모달이란 : 인간과 컴퓨터 사이의 의사소통에 있어서 다양한 형태의 정보를 활용하는 것 (텍스트, 음성, 제스처, 표정 등)
언어학에서 전통적으로 일컫는 모달리티(양태)와는 상당히 다른 의미로 사용되는 듯하다,,
한국어 특화 모델, 다국어로 영역 넓히는 이유
네이버 클로바 CIC 김보섭 연구원은 하이퍼클로바를 다국어 모델로 개발하는 이유를 설명했다. 단순히 모델이 다룰 수 있는 언어 하나를 추가하자는 취지에서 이뤄지는 연구가 아니라는 것.
김보섭 연구원은 "하이퍼클로바 모델 크기가 증가할수록 성능 증가가 둔화된다. 특히 130억 스케일이 넘어가면서부터 심해지는 것을 발견했다. 이러한 현상이 발생하는 이유를 우리는 모델이 규모가 커졌을 때 증가한 파라미터를 효율적으로 활용하고 있지 못하기 때문이라 판단했다"고 설명했다.
그러면서 "학습에 활용하는 말뭉치를 다양하게 늘릴 필요가 있다고 생각했다. 유사한 분포를 따르는 말뭉치를 추가해 학습을 하는 전략은 초거대 언어모델 파라미터를 효율적으로 사용하지 못한다고 가정한 것"이라고 말했다.
한국어 특화 초거대 AI로 개발된 하이퍼클로바는 현재 한국어에서 영어 번역 성능이 영어에서 한국어로의 번역에 비해 떨어지는 상황이다. 한국어 위주 말뭉치로만 학습했기 때문에 영어로 말하는 능력이 부족하다는 것.
기존 다른 초거대AI 모델들에서도 언어 확장이 이뤄졌지만 서양 언어 범위 내에 한정됐다.
결론적으로 연구팀은 타 언어 말뭉치를 한국어 말뭉치와 같이 학습해 하이퍼클로바를 멀티링구얼 하이퍼클로바로 확장하는 연구를 진행하게 됐다. 다양한 언어 가운데 가장 먼저 영어를 대상으로 연구를 시작했다.
하이퍼클로바를 다국어 모델로 확장할 시 얻을 수 있는 효과에는 초거대 AI 주요 한계점인 비용 문제를 개선할 열쇠도 포함된다.
김보섭 연구원은 "하나의 통합된 모델만 학습함으로써 전처리와 학습에 드는 시간을 단축할 수 있다. 다뤄야 하는(serving) 모델 개수 감소로 모델 추론 자원(inference resource)도 절약할 수 있을 것"이라고 전했다.

이미지-텍스트 함께 사용하는 모델 개발 중...한국판 CLIP 될까
(=멀티모달)
올해 DEVIEW에서는 초거대 AI가 언어 이외 이미지 등 다른 형태의 데이터를 다루기 위한 연구 내용도 공개됐다.
멀티모달 모델 구축은 네이버뿐만 아니라 카카오, LG 등 초거대 AI 개발에 뛰어든 국내 기업들이 중요하게 꼽는 후속 연구 주제 중 하나다.
[관련기사]카카오, 공동연구팀과 자사 초거대 AI 'KoGPT' 후속 연구 계획 공개
[관련기사]배경훈 원장, LG 초거대 AI 청사진 공개...내년 초 LG AI 대학원 설립
[관련기사]이미지 인식 AI, 'SEER'와 'CLIP'... 스스로 학습에 연상 능력까지 갖춰
네이버가 현재 개발 중인 멀티모달 모델은 이미지와 텍스트 입력을 받아 텍스트를 출력하는 모델이다. 이미지 속 정보를 반영한 텍스트를 생성하는 능력을 갖추는 것이 관건이다.
이러한 모델을 학습하기 위해서는 서로 연관성이 있는 이미지와 텍스트 데이터가 함께 필요하다. 네이버는 자체 서비스인 네이버 블로그·카페 내 사용자 데이터 일부를 개인정보 마스킹 처리 후 연구에 사용하고 있다.
네이버 클로바 CIC 컨버세이션팀 김형석 연구원은 "이미지 URL 데이터 11억건과 개인정보 마스킹한 텍스트 데이터 5억3000만건에 대해 동일한 기준으로 조율한 뒤 6100만건 이미지-텍스트 URL을 생성했다. 이 중 실제로 이미지 URL로부터 다운로드 성공한 5900만건으로 멀티모달리티 학습 데이터셋을 구축했다"고 전했다.
모델 아키텍처로는 'SimVLM'를 사용하기로 결정했다. 해당 아키텍처는 이미지 패치와 텍스트 토큰을 트랜스포머 인코더에 주입하고 트랜스포머 디코더에서 텍스트 생성하는 인코더-디코더 구조다.
SimVLM : Simple Visual Language Model Pre-Training with Weak Supervision
비전 - 언어 모델링은 시각적 인풋과 연결되는 언어에 대한 이해를 바탕으로 하며, 이는 중요한 제품, 툴의 개발에 도움이 될 수 있다. 일례로, 이미지 캡션 모델은 주어진 사진에 대한 이해를 바탕으로 자연어 설명을 만들어낼 수 있을 것이다.
이러한 크로스-모달 작업에 있어서는 다양한 난관들이 있겠지만, 지난 몇 년 간 비전 - 언어 모델링에 있어서 큰 성과가 있어 왔고, 이는 효과적인 VLP (vision-language pre-training)에 의한 것이었다. 이러한 접근(=VLP)은 시각, 언어 인풋에서 각각 하나의 feature space를 얻는 것 보다, 시각, 언어 인풋 모두에서 동일한 하나의 feature space를 학습하는 것에 목표를 둔다.
이러한 이유로, 현존하는 VLP는 ROI (모델에서 특히 주목하는 특정한 성질)를 따로 떼어서 보기 위해 라벨링 된 물체 지각 데이터셋을 학습시킨 Faster R-CNN과 같은 1. 물체 지각기의 큰 영향력을 싣고 있고, 또 이미지와 텍스트를 함께 학습하기 위해서는 2. task-specific 방식들에 의존해왔다. 이러한 접근 방식(기존의 VLP)은 1. 라벨링 된 데이터셋이나, 2. task-specific 방식을 고안하기 위한 시간을 요구하므로, less scalable하다. (여기서의 scalable이란, 모델의 확장성을 일컫는 듯 하다. 한 마디로 '불편하다')
이러한 난관들을 해결하기 위해서, 이 논문에서 우리는 SimVLP(Simple Vision Language Model의 줄임말) 라고 이름지은 미니멀리스틱하고 효과적인 VLP를 제안한다. 이는 end-to-end (쉽게 말하자면 학습의 인풋과 아웃풋 외의 중간 단계를 뺀)이고, 하나의 objective를 가진 (?) 다는 점에서 언어 모델링과 비슷하고, weakly aligned (?) 이미지-텍스트 페어 데이터로 학습된 모델이다. (이 때, 페어 데이터란 항상 사진과 그 사진에 대한 정교한 설명이 아닐 수 있다)
[End to end deep learning : 네이버 블로그 (naver.com)](https://blog.naver.com/joymychoy/222342252185)
SimVLM의 단순함은 확장적인 데이터셋에의 효율적인 트레이닝을 가능케 하며, 이는 6개의 비전-언어 벤치마크(기준이 되는 모델) 사이에서 최첨단의 성능을 낼 수 있도록 한다. 또한 SimVLM은 합일된 멀티모달 표현을 학습하기에, 제로-샷 문제(학습시에는 한 번도 맞닥뜨리지 못한 데이터에 대해 예측하는 것)에 크로스-모달리티 변환이 파인튜닝 없이, 혹은 텍스트 데이터만 파인튜닝을 해도 가능해진다. 이러한 작업에는 시각적 질의응답, 이미지 캡셔닝, 멀티모달 번역기가 포함된다.
(생략)
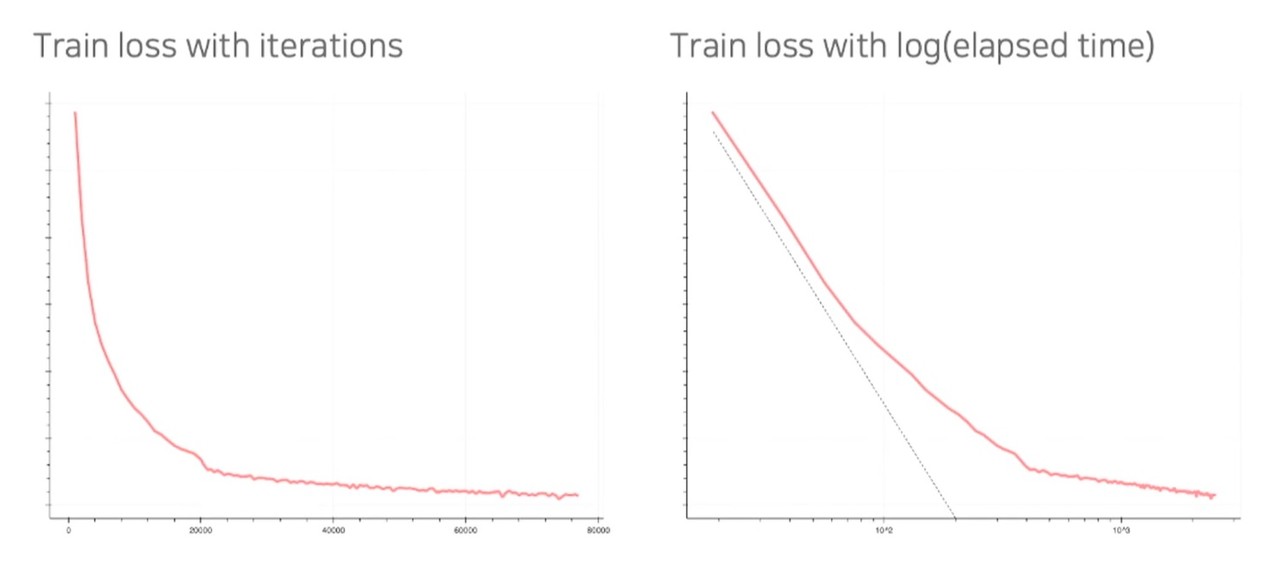
김형석 연구원은 "현재 학습을 진행하고 있으며 학습 로스값도 꾸준히 감소 중이다. 벤치마크 태스크로 아직 정의된 것이 없어 향후 데모를 통해 모델을 선보일 수 있을 것"이라고 전했다.
초거대 언어모델 평가 기술도 직접 만든다
초거대 AI는 규모가 큰 만큼 사람이 성능 평가를 수행하는 것이 현실적으로 어렵다. 기존 자동 평가 기술들은 최근 초거대 AI 모델에 대해서는 다수 한계를 보이고 있는 상황. 품질, 다양성, 유창성, 사실성 등을 평가하는 과정을 거치지 않으면 모델 배포도 지연될 수밖에 없기에 중요한 주제다.
이러한 상황을 타개하기 위해 네이버는 현재 초거대 언어모델 평가 기술을 개발 중이다.
김형석 연구원은 "GLUE, KLUE와 같이 여러 다운스트림 태스크 성능을 통해 언어모델 성능을 간접적으로 측정하는 것이 최선이라 판단했다. 다만 다운스트림 태스크와는 별도로 모델 자체 언어 구사 능력을 평가하기 위한 한 가지 방법으로서 '적대적 평가(adversarial evaluation)' 방법을 사용하는 방법을 연구하고 있다"고 설명했다.
[관련기사]초거대 AI 연구 가속화할 한국어 자연어이해 평가 데이터셋 ‘KLUE’, 어떻게 나왔나
그는 "기술을 보다 개선한 후에는 하이퍼스케일 모델 유창성을 측정하는 매트릭으로 사용할 예정이다. 이를 위해 현재 해당 지표를 평가 파이프라인에 포함해 다른 벤치마크 태스크와의 연관성을 관찰하고 견고성을 개선하는 연구를 진행하고 있다"고 전했다.
적대적 평가는 튜링테스트에서 착안한 기술이다. 사람이 대화를 통해 기계와 사람을 분류하듯이 기계가 기계와의 대화로 기계 혹은 사람 여부를 판단하는 방식이다.
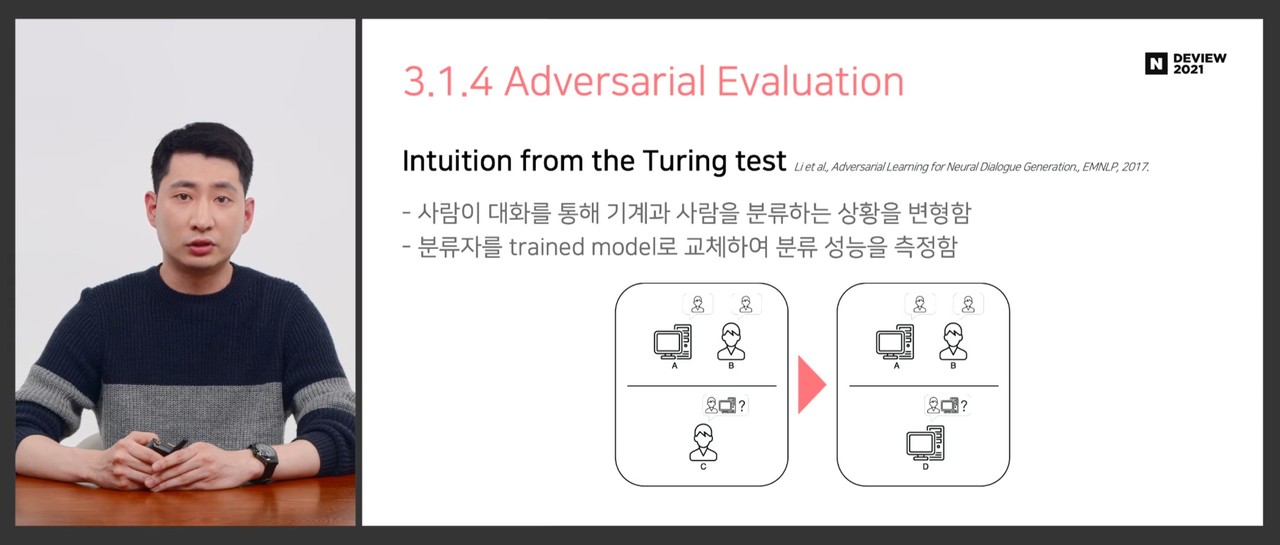
김형석 연구원은 "GAN과 상당히 유사한 구조인데, 다만 분류자(discriminator)의 변화도(gradient)를 생성자(generator)에 전달(propagation)하지 않는다는 점에서 차이가 있다. 특히 우리가 구현한 아키텍처에서는 여러 생성자를 사용해 차별화했다"고 전했다.
'etc > IT 뉴스' 카테고리의 다른 글
| [211105] "전문가 수준의 영어 문제, AI가 5초 만에 제작"...이형종 렉스퍼 대표 인터뷰 (0) | 2021.12.06 |
|---|---|
| [211202] 카카오, 디지털 헬스케어 CIC 설립...대표는 황희 분당서울대병원 교수 (0) | 2021.12.06 |
| [211028] 네이버, AI 기술 적용한 새로운 검색 서비스 '에어서치' 공개 (0) | 2021.11.01 |
| [210827] 엔비디아, 일상적인 추천시스템에 GPU 시대 연다... 특화된 '멀린 프레임워크' 내놔 (0) | 2021.08.31 |
| [210822] 스탠퍼드대 연구진, "대규모 언어모델이 편향성 강화하고 심각한 환경 오염 발생시켜" (0) | 2021.08.27 |




댓글